論文読み - Language Models are Few-Shot Learners
今回は OpenAI が 2020 年に発表した GPT-3 に関する論文 “Language Models are Few-Shot Learners”1 を読みました。
導入
GPT-3 は 175B パラメータを持つ言語モデルで、そのパラメータ数は GPT-2 の 1.5B に比べて 100 倍以上も大きい。
すでに GPT-1,2 などの先行研究によってパラメータ数が増えることで特定タスクの性能が対数線形的に向上することがわかっており(スケーリング則)、まだ saturation point に達していないことが示唆されていたため、もっと大きなモデルを作成することでさらなる性能向上が期待されていたという背景がある。
メタ学習 / In-Context Learning
GPT-1 では事前学習モデルをファインチューニングすることで特定タスクに適応させることができた。
しかしファインチューニングには追加で学習をさせるという時間がかかってしまう問題がある。
GPT-2 では、パラメータを増やしたことによって学習データから暗黙的に幅広いタスクを認識することができるようになり、ファインチューニングをせずとも、単に入力されるプロンプトに埋め込まれた指示に従って推論時に特定タスクに高速に適応して適切な出力を生成することができるようになった。
例えば論文 Figure1.1 のように、プロンプトに埋め込まれた「演算を繰り返す」文脈や「単語を変換する」文脈に従って、それに続く未知の問題に対しても適切な出力を生成することができる。
この手法を メタ学習 もしくは In-Context Learning と呼ぶ。
今までのモデルのスケーリング則による性能向上が、In-Context Learning でも同様に適用されるのではないかという検証が今回の GPT-3 の目的である。
論文 Figure 1.2 より、モデルが大きければその分プロンプトの文脈をより深く理解し活用できていることが示されている。
論文 Figure 1.3 より、全 42 個のタスクに対して、パラメータが増えれば増えるほど性能が向上していることが示されている。さらに、Zero Shot や One Shot よりも、Few Shot の方が性能の向上度合いが大きいことから、パラメータを増やすことによってコンテキストの理解度が向上することが定量的に示されている。
モデルのアーキテクチャ
GPT-3 は GPT-2 と同様に Transformer に基づいているが、いくつかの変更点がある。
まずこの巨大なモデルを学習するためにメモリ使用量・計算量削減をする工夫として Sparse Transformer2 に似たレイヤーが導入されている。
Reformer3や Longformer4と同じアイデアらしい。
NOTE
Sparse Transformer の論文 “Generating Long Sequences with Sparse Transformers” の Figure 3 に視覚的な従来の Transformer と Sparse Transformer の比較が示されている。
従来の Transformer は全てのトークン間の関係を計算するため計算量が となるが、Sparse Transformer は近傍のトークン間のみの関係を計算するため計算が枝刈りされて となる。
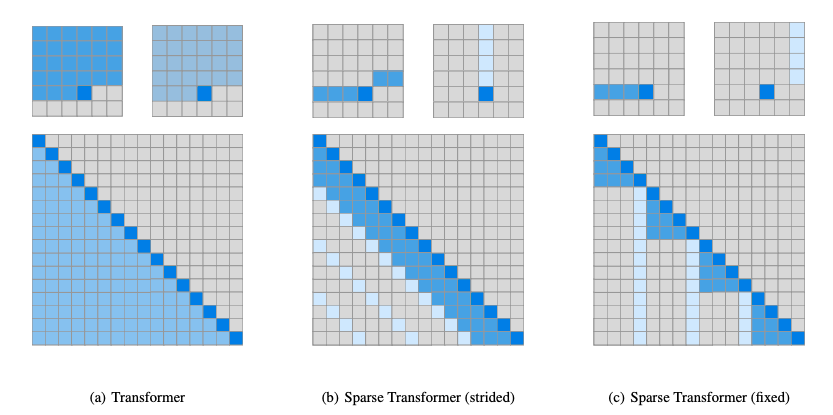
おそらくこの Sparse Transformer のような文全体ではなく一部だけ抽出した (N-gram みたいに?) トークン部分列に対して内積計算を行うことで、モデルの学習を高速化しているのだろう。
以前の研究5により十分なトレーニングデータがあれば、検証損失のスケーリングはモデルサイズの関数としておおよそ滑らかなべき法則になるということがわかっている。(スケーリング則)
このスケーリング則が GPT-3 にも適用されるかどうかを検証するために、GPT-3 を作る過程で 125M, 350M, 760M, 1.3B, 2.7B, 6.7B, 13B, 175B の 8 つのモデルを作成した。
データセット
GPT-3 は 1 兆語近くからなる Common Crawl から他の高品質なコーパスとの相関によってフィルタリングし品質を向上させたものに既存の高品質な WebText や Books1,2, Wikipedia などを追加して学習した。
最終的には 570GB (4000 億トークン) のデータセットを用いて学習した。
評価
GPT-2 の評価方法と同様なコンテキストに埋め込む、Zero Shot, One Shot, Few Shot 手法における性能を評価した。
論文 Figure 3.1 にあるように Validation Loss は Compute (FLOP) に対してスケーリング則に従っていることが示されている。
黄色(GPT-3 最大モデル)は予測線の途中で切れてしまっているがこれは予算が足りなかったためであり、続けて学習させればスケーリング則に従いそうである。
PTB
Table 3.1 では既存のベンチマーク PTB(Penn Treebank) において PPL(Perplexity) が Sota から 15 ポイント以上も向上し、モデルサイズの影響で相当な性能向上があったことが示されている。
LAMBADA
LAMBADA という文末の最後の 1 単語を予測するタスクにおいても、モデルサイズが大きくなるほど性能が向上していることが示されている。
論文ではこれを解くために
Alice was friends with Bob. Alice went to visit her friend ___. -> Bob
George bought some baseball equipment, a ball, a glove, and a ___. ->
のような文脈を与え、Zero Shot, One Shot, Few Shot で性能を評価している。
Table 3.2 にあるように、Shot 数が増えるほどやはり性能が向上しており、ACC では SoTA から 15% 程度の改善、PPL では 6 ポイント程度のかなりの改善があった。
Figure 3.2 ではその性能がパラメータのサイズに応じて安定して向上していることが示されている。
HellaSwag, StoryCloze
HellaSwag と StoryCloze はどちらも Common Sense Reasoning のタスクであり、コンテキストに最も適した結末の選択肢を選ぶタスクである。
こちらは SoTA は達成しなかったものの、SoTA のモデルはファインチューニングを行っているのに対して、GPT-3 は事前学習のみの In-Context Learning であることを考えると、かなりの性能を発揮していると言える。
(… 評価項目が多すぎたので飛ばす。色々な項目でやばい性能がでたよ的なことが書いてある)
このモデル・研究が与える影響
GPT-3 は SoTA の性能を達成するだけでなく、ファインチューニングを行わずとも In-Context Learning によって高い性能を発揮することが示された。その性能が与える社会的影響への懸念が述べられている。
悪用が予想されるアプリケーション
誤報・スパム・フィッシング・法的政治的プロセスへの利用・学術論文の生成など、悪用が予想されるアプリケーションがある。
すでに GPT-3 は人間が書いたテキストと区別ができないほどの文章を数段落生成することができてしまうため、質の低いミスリードを生んでしまうコンテンツを生成してしまい、それをそのままアプリケーションへ応用されると、社会的な問題を引き起こす。
公平性・バイアス
GPT-3 は大量のデータセットから学習するため、そのデータセットに含まれる偏見や差別を反映することがある。
例えば性別に関連する GPT-3 の評価では、「議員・銀行員・教授」といった職業に対して男性を、一方で「助産師・看護師・受付係」といった職業に対して女性を関連付ける傾向があったり、そもそもデータセットが持つ文章が男性側に偏ることから性別識別子の次予測では男性を選びやすいというバイアスがあったりすることがわかっている。
エネルギー消費
GPT-3 は巨大なモデルであるため、その学習には膨大なエネルギーが必要である。
ただ、一度大規模な事前学習モデルを作ってしまえばそれ以降のモデル構築がより効率的で容易になるため、大規模モデルを作ることが一概にリソースの無駄遣いであるとは言えない。
さらに model distillation6 などの最適化の研究が進んでおり、他の NN 分野にもみられるようにアルゴリズムの進歩によって自然に効率が向上する可能性もある。
そのため、作るモデルとそのモデルの社会的インパクトを天秤にかけて慎重に検討する必要がある。
まとめ
175B パラメータを持つ GPT-3 は Zero Shot, One Shot, Few Shot において SoTA の性能を達成し、ファインチューニングを行わずとも In-Context Learning によって高い性能を発揮することが示された。
これほどの大きなモデルであってもパフォーマンスがスケーリング則に従うことが示されため、学習前に大まかな性能予測をすることができることが示された。
しかし同時に、その性能が与える社会的影響への懸念も示されており、モデルの作成とその社会的インパクトを天秤にかけて慎重に検討する必要があることが示された。
Footnotes
-
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei, “Language Models are Few-Shot Learners”, 2020 ↩
-
Rewon Child, Scott Gray, Alec Radford, Ilya Sutskever, “Generating Long Sequences with Sparse Transformers”, 2019 ↩
-
Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya, “Reformer: The Efficient Transformer”, 2020 ↩
-
Iz Beltagy, Matthew E. Peters, Arman Cohan, “Longformer: The Long-Document Transformer”, 2020 ↩
-
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, Dario Amodei, “Scaling Laws for Neural Language Models”, 2020 ↩
-
Xiaodong Liu, Pengcheng He, Weizhu Chen, and Jianfeng Gao, “Improving multi-task deep neural networks via knowledge distillation for natural language understanding”, 2019 ↩