論文読み - Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
言語モデルを強化学習の方策モデルとして利用するという分野に興味を持ったので “Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning”1 を読みました。
導入
近年の大規模言語モデルは世界の物理現象を捉える能力を発揮して、いわゆる 常識的な推論 ができるようになってきている。
この能力を活用して近年 LLM により意思決定問題を解決する研究が盛んに行われている。
しかし、LLM は知識を適切に具体と結びつけることが適切にできていない、つまり グラウンディング 2に欠点がある。
結果、尤もらしい表現の全く事実と異なる内容の文章を生成することがある ハルシネーション が発生する。
- そもそも次単語予測が基本の学習プロセスであるため、問題解決をする動機付けがない
- 因果関係を捉えるための 環境への介入ができない
- 環境との相互作用の結果をフィードバックとして 追加で学習することができない
ことが原因だと論文で考察されている。
問題設定
そこで強化学習の特徴である「エージェントが環境と相互作用する」という特性を利用し以下の問を設定する。
- LLM をポリシーとして利用できるか
- 環境との相互作用の結果それを新たに知識として学習できるか
検証項目は以下の通り
- サンプル効率
- 与えられたプロンプトのナビゲーションにいかに早く適応して学習できるか
- 事前学習された知識はサンプル効率を向上させるのか
- 新たなオブジェクトへの一般化
- 実際に訓練された後、その内容とは異なる別の新たなオブジェクトに対しての汎化能力を持つか
- 新たなタスクへの一般化
- 実際に訓練された後、その内容とは異なる別の新たなタスクに対しての汎化能力を持つか
- オンライン学習の影響
- 専門家データ(Expert Trajectory)によるオフライン模倣学習と比較して、オンライン RL がグラウンディングに経験的な影響を与えるか
GLAM: Grounding LLM with Online RL
本論文では、GRounding LAnguage Models (GLAM) という方法を提案している。
GLAM 法では、LLM をポリシーとして利用し、オンライン RL を用いて対話的環境でグラウンディングを行い、収集した観察と報酬から言語で定式化された目標の達成に向けて自己を改善させる。
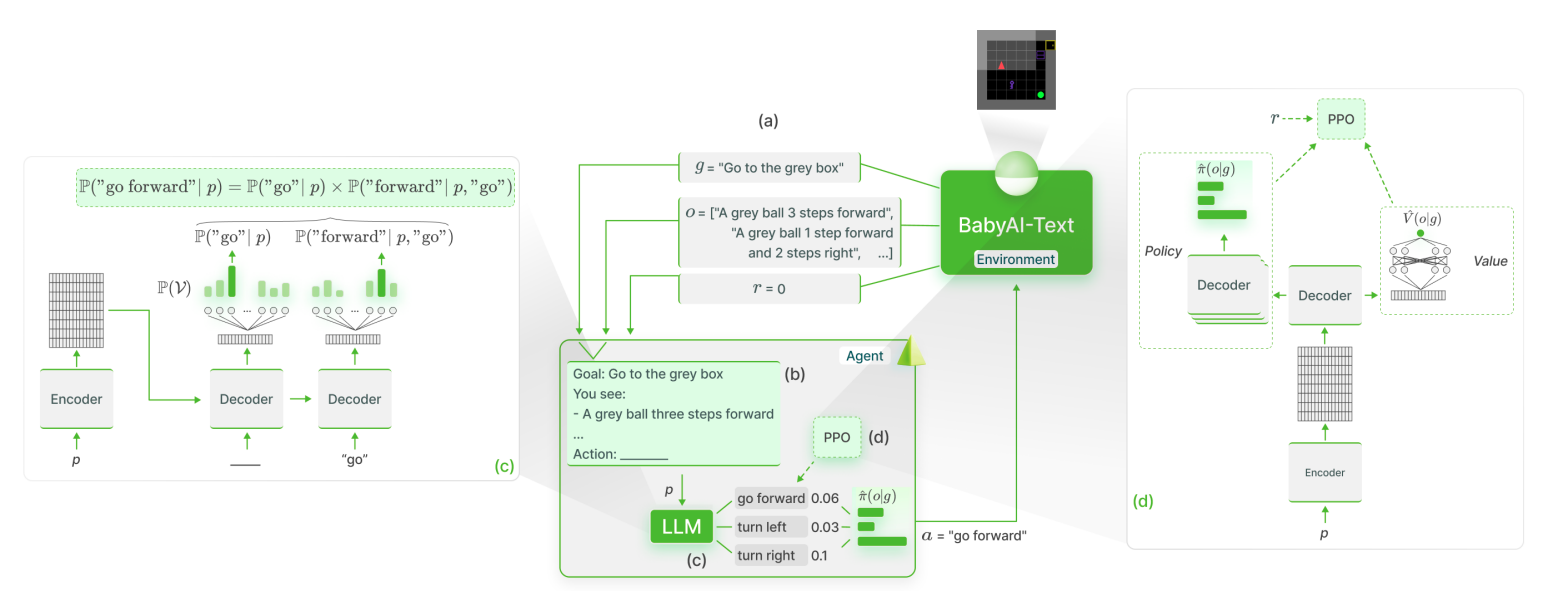
問題提起
パラメータは以下の通り
- 言語ボキャブラリー
- 行動
(トークン系列としての行動) - 観測
- 報酬
- 報酬を条件付けるタスクや目標の記述
- 状態空間
- 行動空間
- 目標空間
- 遷移関数
- 報酬関数
- 観測関数
- 割引因子
これらをもとに、目標拡張部分観測マルコフ決定過程(POMDP) として環境をフレーム化する。
NOTE
マルコフ決定過程(MDP)は、決定の最適化問題を解くための数学的フレームワークであり、状態において行動を取ることで報酬を得るという遷移関数と報酬関数が定義されている。
MDPは全ての状態が観測できることが前提となっているが、部分観測マルコフ決定過程(POMDP)は状態が完全には観測できない場合を仮定したものである。
本研究では、言語学習のために設計された BabyAI を BabyAI-Text というテキストのみに拡張したフレームワークを提案している。
6 つのテキストコマンド (左に曲がる、右に曲がる、前進、拾う、落とす、トグル) を使用して、エージェントがオブジェクトと相互作用する際に部分的観測を示す BabyAI-Text のテキスト記述 を用いて、グラウンディング方法を評価している。
LLMをポリシーとしてインタラクティブな環境に適応する
プロンプトエンジニアリングやファインチューニングによってより性能を改善する可能性はあるが、今回はあえて Appendix.C のシンプルなプロンプトを採用している。
プロンプトを与えられると、LLM は行動可能なアクションの確率分布を出力する必要がある。
エンコーダの最終層に出力がとなるような MLP を追加することもできるが、今回はより直接計算するために各アクションに対応するフレーズの出力確率を利用する。
- : アクション ()
- : プロンプト
- : アクションに対応するフレーズの番目の単語
例えば “go forward” というアクションに対してなら
となる。
計算量が命令文の系列長回倍であることが欠点だが、追加学習やアーキテクチャの変更を必要としないため 任意の行動空間に適用可能であり堅牢である。
最終的にはこれを softmax をとることで確率分布を得る。
PPOによるファインチューニング
以上の仕組みにより、LLM をポリシーとしてインタラクティブな環境に適応することができ、経験を収集することができたため、次にグラウンディングを行う。
任意の目標 に対して、期待される割引報酬の総和を最大化するポリシー を学習することを目指す。
このために、Proximal Policy Optimization (PPO)3を用いてファインチューニングを行い、行動ポリシーと価値関数を学習し真の価値に近似させる。
近似のためこちらのネットワークにはデコーダオブロックの最終層の上にスカラー出力となる MLP を追加してを出力する。
Lamorel を使った分散LLMポリシー
非常に大きな LLM を用いて行動空間上の確率を計算するのは明らかに計算量が多い。そのため、LLM ワーカーを Python のライブラリである Lamorel を用いて分散させ、アクションのサブセットをスコアリングすることで分散推論を可能にしている。
実験方法
学習に使われているコーパスがインストラクションタスクを含んでおり環境との対話がしやすいモデルであること、またオープンソースであるためにFlan-T5 780Mを実験に使用した。
比較のために 3 つのベースラインを用意している。
- NPAE-Flan-T5
- Non-Pretrained with Action heads and Embedding Flan-T5
- 事前トレーニングされた埋め込み層のみを再利用し、アクションヘッド(行動の確率分布を出力する部分)を追加したモデル
- 事前学習で得た知識がタスクのグラウンディングに与える影響を評価するため
- DRRN4
- 古典的な RL ベースラインとして、1M パラメータのエージェントである
- テキストゲームの状態と行動を自然言語で表現しこれらの関係を捉える NN により Q 関数を学習し近似する手法
- 非 LLM の SOTA との比較のため
- Symbolic-PPO
- トークンなどのシンボルによって直接表現された環境で PPO を学習するベースライン
- 自然言語での表現がどれだけ有効かを評価するため
また、本モデルを GFlan-T5(Grounded Flan-T5)と呼ぶ。
与えるプロンプト
各ステップで BabyAI-Text から返された情報を次のようなプロンプトとして埋め込み、入力する。
エージェントの行動
どのような行動が可能かのリストアップをしたヘッダーを与える
Possible action of the agent: <list of actions>エージェントのゴール
Goal of the agent: <goal>エージェントの観測
観測情報は前 3 つの観測と 2 つの行動を短期記憶(Short-term memory)として利用する。
(DRRN では Short-term memory を利用するために RNN を使用している)
Obs. 0: <description from BabyAI-Text at step t − 2 >
Action 0:<action chosen by the agent at step t − 2 >
Obs. 1: <description from BabyAI-Text at step t − 1 >
Action 1: <action chosen by the agent at step t − 1 >
Obs. 2: <description from BabyAI-Text at step t >
Action 2: <the next action to be chosen by the agent>結果
タスクに適応する速さ
問 1 のサンプル効率について、いかに LLM が早くタスクに適応して学習できるかを評価した。
BabyAI-Text において 1.5M ステップの学習をする。
各エピソードは以下の 5 タスクからランダムに選択される。
- Go to <object>
- Pick up <object>
- Put <object A> next to <object B>
- Pick up <object A> then go to <object B> and Go to <object B> after pick up <object A>
- 命令の時系列に基づいた行動の行動を要求するタスク
- Unlock <door>
- ドアを開けるには鍵が必要であることの推測、正しい鍵の発見とナビゲーションが必要
もちろん環境にはタスク達成には関係ない不要な object も含まれているため、手続きを正しく理解することが求められる。
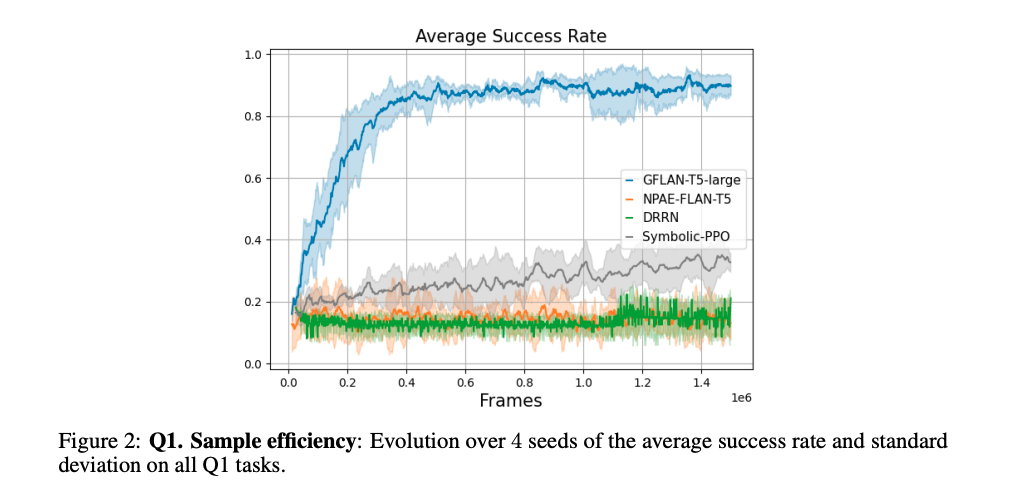
論文図 2 では、学習ステップ数に対するタスクの成功率を示している。
- GFlan-T5 は 0.25M ステップで成功率が 0.8 に達し、0.6M ステップで 0.9 に達している
- DRRN や NPAE-Flan-T5 は 1.5M ステップでも 0.2 に達せず、Symbolic-PPO は 1.5M ステップで 0.4 に達そうとしている
この結果から圧倒的に GFlan-T5 がサンプル効率が高いことがわかる。
NPAE-Flan-T5 との比較により、GFlan-T5 は LLM の事前学習によって知識を有効活用できていることがわかる。
また、Symbolic-PPO との比較により、言語が学習を支援するツールとしていかに有効であるかがわかる。
図 7 に示されているように、当初 DRRN が PPO よりもサンプル効率が高いと予想されていたが、実際には PPO の方がよりサンプル効率が高いことがわかった。
観測情報を PPO は記号情報で、DRRN はテキストで取得するため、言語レベルの高モーダル性がある場合であっても、空間情報と言語の関連を理解することは難しいと考えられる。
したがって言語の両方を同時に学習させることがいかに逆効果であるかを示していると言える。
また、図 18 と表 2 ではより詳しく GFlan-T5 が学習する過程を示している。
次に行動空間と余計なオブジェクトの数(distractors)を変化させてサンプル効率がどのように変化するかを評価した。
今回は指標としてサンプル効率測定指標 SE (Sample Efficiency) を導入している。
これは各ターンでの成功率の平均値であり、以下の式で定義される。
- : ステップ数(フレーム数)
- : ステップでの成功率
行動空間のサイズが与える影響
turn left, turn right, go forward という 3 つの行動しか必要ないタスクにおいて、
- The restricted action space
- 3 つの行動のみを Available actions として与える
- The Canonical action space
- このタスクにおいて可能な全ての行動(
pick up,drop,toggle)を Available actions として与える
- このタスクにおいて可能な全ての行動(
- The augmented action space
- このタスクにおいて可能な全ての行動 + 余計な行動 (
sleep,do nothing,think)を Available actions として与える
- このタスクにおいて可能な全ての行動 + 余計な行動 (

図 3 (a)はその結果を示している。ベースラインの 3 つは状態が増えるにつれてサンプル効率が低下しているのに対し、GFlan-T5 は状態が増えると逆にサンプル効率が向上していることがわかる。
論文では ファインチューニング時に無駄な行動を素早く捨てることができているため ではないかと考察している。
余計なオブジェクトの数が与える影響
次に余計なオブジェクトの数が与える影響を評価した。
図 3 (b)はその結果を示している。GFlan-T5 は 4->12 に増えると約 14%のサンプル効率が低下を示しているのに対し、Symbolic-PPO は約 38%の低下を示している。
論文では LLMは環境の関連する側面に迅速に集中することができるため ではないかと考察している。
新しいオブジェクトへの一般化
問 2 の新しいオブジェクトへの一般化について、BabyAI-Text 環境で訓練された後、学習時には存在しなかった新しいオブジェクトに対してスキルを一般化できるか(いわゆるゼロショット性能)を評価した。
※オブジェクトの識別性能に期待しているわけではなく、幾何的な関係(配置の位置関係など)を理解することができているかを評価している。
図 4(Q2)の結果より、新しいオブジェクト、つまり新しい名詞が観測結果に渡された場合でも、GFlan-T5 はほとんど性能低下がない(-2%)。
また、存在しない形容詞や名詞を使った場合でもほんの少しの性能低下(-13%)に抑えられている。
これは 幾何的な説明をする in front や距離尺度を表現する steps などの単語を捉えるように学習しているため に対応できているのではないかと考察している。
新しいタスクへの一般化
問 3 の新しいタスクへの一般化について、BabyAI-Text 環境で訓練された後、学習時には存在しなかった新しいタスクに対してスキルを一般化できるか(いわゆるゼロショット性能)を評価した。
図 4(Q3)の結果より、以下のことが分かった。
似ている完全に新しい命令を与えられた場合、GFlan-T5 は性能はかなり低下するものの依然として他のベースラインよりも高い性能を示した。
次に、同じタスクを学習しているが同義語の別の行動(go forward を move ahead へ置き換えるなど)を与えることでロバスト性を評価した。
単語埋め込み空間に行動がマッピングされているため問題なく対応できるということを期待したが、パフォーマンスが 87%も低下してしまった。アクションの語彙に過剰適合しているためだと考えられる。
最後に、新たな言語(論文ではフランス語)で環境や行動を与えることでロバスト性を評価した。
論文では 一度に多くのシンボルが変更されると新たなシンボル間での関係性を捉えられないから ではないかと考察している。
オンライン学習の影響
問 4 のオンライン学習の影響について、オフライン模倣学習(BC)と比較して、オンライン RL がグラウンディングに経験的な影響を与えるかを評価した。
ベースラインとして GFlan-T5 から収集された遷移を模倣学習した BC-GFlan-T5 や成功率が 1 の BabyAI の手続的 Bot を使用して模倣学習した BC-Bot を用意した。
環境との相互作用によって試行錯誤を通じた学びを得ることでグラウンディングの改善が期待される。
結果同じ遷移を経験していたとしても環境との相互作用を経験した GFlan-T5 の方が BC-GFlan-T5 よりも高い性能を示した。
まとめ
LLM を用いた環境との相互作用を通じたグラウンディング方法である GLAM を提案し、その結果サンプル効率と新しいオブジェクトや複数の新しいタスクに対するゼロショットテストの一般化能力の両方が向上することが示された。
今回はテキストのみを観測として利用したが、画像や音声などの他のモダリティを組み合わせることでより多様な環境に適用できる可能性がある。
ただし今回の実験はかなり制限された環境であるため、より実用的な環境でのもっと大きい行動空間などにスケールした場合にどれだけ適用できるかを今後追調査していく必要がある。
Footnotes
-
Thomas Carta, Clément Romac, Thomas Wolf, Sylvain Lamprier, Olivier Sigaud, Pierre-Yves Oudeyer, “Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning”, 2023 ↩
-
AI が知識や情報源をもとに生成内容を裏付けること ↩
-
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, Oleg Klimov, “Proximal Policy Optimization Algorithms”, 2017 ↩
-
Ji He, Jianshu Chen, Xiaodong He, Jianfeng Gao, Lihong Li, Li Deng, Mari Ostendorf, “Deep Reinforcement Learning with a Natural Language Action Space”, 2016 ↩